Three concurrency models in mainstream languages
As Fred Brooks famously said, there are is no Silver Bullet to developing software. Most of the software development over the past decade, has focused on reducing the accidental complexity of software development, starting from Dijkstra’s Notes on Structured Programming to Object Oriented Programming, a term coined by Alan Kay, to the current resurgence of interest in Functional Programming.
In today’s world, Moore’s law has meant that computers have started going multicore. This has implied that in order to scale, and make better use of the hardware, programs have had to be beyond sequential models of execution. As we have learnt from practice, doing shared memory parallelism, with locks is very very hard.
So, the question arises, is there something we can do to improve the ability to compose these kinds of non-sequential programs?
One way to think about it, is not to start with parallel programs, but instead start with concurrent programs, and then automatically find ways to make these concurrent programs parallel based on the available resources on the computer. The seminal paper on concurrency was the Communicating Sequential Processes by C. A. R. Hoare. This described a model and theory for how to represent and reason about concurrent computation.
One interesting way to think about this problem is to consider the following conceptual model.
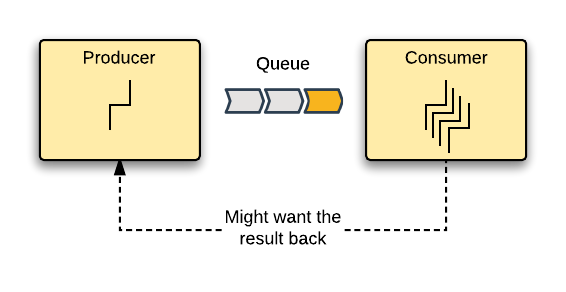
Here we have one execution context that wants to hand-off a computation to be performed concurrently. We could call this the “Producer” of the computation. The computation itself, could have some data associated to it, and this data is normally referred to as a “message”, and for most practical purposes, put in a “Queue” or “Channel” to be processed. We then have the other execution context, the concurrent part, which we call the “Consumer” here, which receives these messages, processes them and produces new values. Finally, the original producer of the computation might or might not want the results of the computation back, and if so, we need to reason about how it get’s it, once the computation has been completed.
It turns out, that based on which aspect of this model you concentrate on, namely, the processes that are initiating and receiving the computation (Producers and Consumers), the Queue or channel on which the communication is performed or the Value’s being computed, you can see the three dominant styles of concurrency in mainstream languages today.
Erlang
Erlang is one of the oldest languages to directly take on the problem of concurrency. The main driver for this innovation was the need to build large, complex telephony systems for Erricson. If you have not already seen, the following “Erlang: The Movie” is a treat to watch.
The core idea in Erlang was to concentrate on the “Process” part of the model and have the language provide the
mechanism for communicating between these processes. The concurrency model in the language is supported by three
primitives, namely, spawn to create a new process and get it’s process id, called a PID, ! to send a message
to a given process by it’s PID and receive for processes to receive the messages sent to them. By definition, send
is defined to be asynchornous.
When a message is sent, it is put on the receiving processes mailbox as it might or might not be running at that time. The processes themselves are very lightweight, and the VM takes care of scheduling them, with pre-emptive suspension based on the number of reductions (or steps) being performed by each process. This very nice blog post talks about the details of how the scheduler works and how the processes are multiplexed across multicores.
As can be seen above, programmers don’t have any direct control over the mailbox (Erlang terminology for the Queue). They can only control processes. Erlang in addition heavily builds on the functional style or programming, using things like pattern matching to differentiate and destructure the messages on the receiver side. It also contains battle tested libraries, like the OTP to improve the reliability of these programs, but that is a topic for another day! (For some details, see the Systems that never stop talk by Joe Armstrong).
From Erlang getting started documentation, here is a simple example of a ping-pong server in Erlang.
-module(tut15).
-export([start/0, ping/2, pong/0]).
ping(0, Pong_PID) ->
Pong_PID ! finished,
io:format("ping finished~n", []);
ping(N, Pong_PID) ->
Pong_PID ! {ping, self()},
receive
pong ->
io:format("Ping received pong~n", [])
end,
ping(N - 1, Pong_PID).
pong() ->
receive
finished ->
io:format("Pong finished~n", []);
{ping, Ping_PID} ->
io:format("Pong received ping~n", []),
Ping_PID ! pong,
pong()
end.
start() ->
Pong_PID = spawn(tut15, pong, []),
spawn(tut15, ping, [3, Pong_PID]).
Java
The Java view of asynchronous and concurrent programming, which has been evolving over the last few years, has mostly been focusing on the Value being produced. Java originally just started with threads and locks, and programmers had to build abstractions on top by hand. But the past few years, this has been evolving with the introduction of Future and Executor models.
In this model, both the Queue and the Process become implementation details, with the actual value,
represented by Future<V>, which can be understood as a future value of type V produced by a defered
computation, becomes the main axis of control and composition.
All composition, like chaining and flow of control are then based around this Future abstraction. So the
same ping-pong example we saw above, represented based on Values, in Java would look as follows:
package org.satyadeep.pingpong;
import com.google.common.util.concurrent.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Application {
static class Ping implements AsyncCallable<Integer> {
private final int value;
private final ListeningExecutorService exec;
public Ping(int value, ListeningExecutorService e) {
this.value = value;
this.exec = e;
}
@Override
public ListenableFuture<Integer> call() throws Exception {
if (value == 0) {
return Futures.immediateFuture(0);
}
System.out.println("ping on thread " + Thread.currentThread().getId());
return Futures.submitAsync(new Pong(value, exec), exec);
}
}
static class Pong implements AsyncCallable<Integer> {
private final int value;
private final ListeningExecutorService exec;
public Pong(int value, ListeningExecutorService e) {
this.value = value;
this.exec = e;
}
@Override
public ListenableFuture<Integer> call() throws Exception {
System.out.println("pong on thread " + Thread.currentThread().getId());
return Futures.submitAsync(new Ping(value - 1, exec), exec);
}
}
public static void main(String[] args) throws Exception {
final ExecutorService baseExec = Executors.newFixedThreadPool(2);
final ListeningExecutorService exec = MoreExecutors.listeningDecorator(baseExec);
ListenableFuture<Integer> s = Futures.submitAsync(new Ping(3, exec), exec);
s.get();
baseExec.shutdown();
}
}
Interestingly, .NET follows a similar model with the Task abstraction for asynchronous computation.
Unlike in Erland and Go, though Java does have a VM, the scheduling of the threads is done natively at the OS level, just like in the case of .NET.
Go
Finally, in recent years, we have the Go model, which focuses on the Queue, which is called a channel
or chan in the language. For an good overview, see the following talk by Rob Pike, titled
“Concurrency is Not Parallism”.
In this model, the actuall processes, called go routines in the language, don’t provide any control other
than the ability to start them. All control and composition is done based on channels, which are passed as input to
these go routines, and the language provides native ability to read and write from these channels across the different
go routines.
package main
import (
"sync"
"fmt"
)
func main() {
var w sync.WaitGroup
pingChan := make(chan bool)
pongChan := make(chan bool)
w.Add(1)
go ping(&w, 3, pingChan, pongChan)
w.Add(1)
go pong(&w, pingChan, pongChan)
w.Wait()
}
// ping gets a read-only channel pingChan and a write-only channel pongChan.
// when it starts, upto nPing times, it first send a ping over the pongChan
// and waits to hear back a pong on the pingChan. Once done, it closes the
// pongChan.
func ping(w *sync.WaitGroup, nPing int, pingChan <-chan bool, pongChan chan<- bool) {
for i := 0; i < nPing; i++ {
fmt.Println("ping")
pongChan <- true
<- pingChan
}
close(pongChan)
w.Done()
}
// pong gets a write-only channel pingChan and a read-only channel pongChan.
// Essentially the mirror image of ping. It keeps looping as long as there
// is a value to be read from the pongChan and replies back to every value
// on the pingChan.
func pong(w *sync.WaitGroup, pingChan chan<- bool, pongChan <-chan bool ) {
for {
if _, ok := <-pongChan; ok {
fmt.Println("pong")
pingChan <- true
} else {
break
}
}
w.Done()
}
As can be seen above, the go routines don’t have any context on whether there are any other go routines running or how to communicate with them. The only lever of control are the channels themselves. There could be one or more producers and consumers working off the channels, but that is transparent to the routines that are sending or receiving data from these channels.
Interestingly, the channels also act as the synchronization primitives in Go. By default, they are unbuffered, which means that a send could block if there are no active receivers. It is also possible to created buffered channels, that would only block if the buffer fills up.
Like in the case of Erlang, the go routines are scheduled by the runtime and multiplexed across the different cores (and internal threads). But unlike Erlang, Go does not use preemptive scheduling, but instead depends on some form of work stealing scheduler, where the go routines are swapped out at specific interesting points, like when they do I/O or attempt to communicate over a channel.