Concurrency in practice - Go programming language
Continuing our exploration of the various concurrency models, the Go programming language is one of the more recent ones that explicitly supports concurrency as a first class concept. From the implementation of go routines as cheap ways to launch and run concurrent code, to channels to communicate between them, it makes reasoning about and writing concurrent code not only easy, but fun!
In this post, we will look at a small I/O intensive problem and explore different ways of doing this operation concurrently using the Go programming language, as a practical way of using concurrency in practice. The final code is hosted on Github at satyasm/gopagesize, and if you have a working Go environment, you can get it by running
go get github.com/satyasm/gopagesize
which should give you the gopagesize command to play with.
Problem Definition
Say, we have a list of webpage URLs, and we want to find out what the size of the webpage is.
We can define the size of the webpage as the size of the original HTML for the page, along with
the size of all the assets it references, namely, css, image and js files in link, img and
script tags respectively. So the idea is that given a webpage URL, fetch the page, parse the
HTML to find the references as above, download those resources and finally sum the total size of
the bytes received to get the total page weight.
The different possible models of concurrency in solving this problem can be visualized as follows:
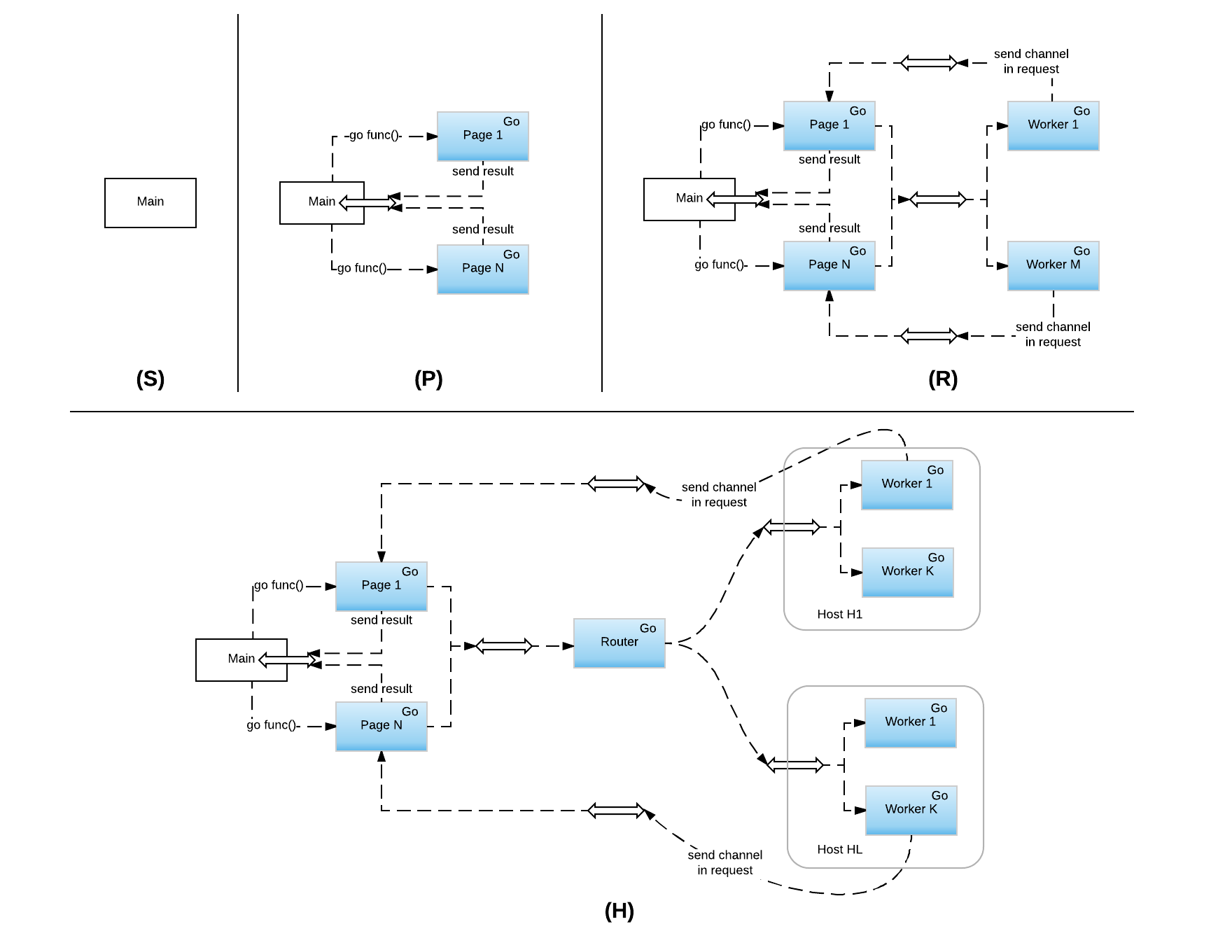
The blue colored boxed in the picture represent go routines that have been started and the double ended thick arrows represent channels for communicating between them. The different models being
- Synchronous (S): This is the simplest model where we fetch everything sychronously. We loop through every web page URL, and for each URL, we then fetch and parse the HTML, indentify the external resources and then iteratively fetch them to find the final page size. The code for this look as follows:
- Page Level Concurrency (C): This is the first step up from the synchronous model, wherein we take each input webpage and then resolve it in it’s own go routine. So each of the web pages run concurrently, but for any given pages, the resources are fetched synchronously one after the other as above.
- Resource Level Concurrency (R): This extends model (C), but having a pool of go routine “workers” for doing the HTTP GET operations. Like above, each web page run’s in it’s own go routine, but in order to do the HTTP operations, it hands it off to a pool. The workers in the pool concurrently do the fetch and once data is received, it’s sent back to the page level go routine for processing. This model has the interesting property of bounding the number of concurrent HTTP requests in progress at any given time globally.
- Host Level Concurrency (H): This further builds on model (R), by having a pool of concurrent routines per host instead of a global pool of workers. In this model, the page level go routine, instead of handing it of directly to a pool, hands it to a router instead which then multiplexes it across the different pools based on the host name in the request.
Fetching a web page and it’s resources is clearly an I/O intesive operation and as sucn the synchronous model (S) will not only be slow, but also mostly idle, waiting for data to come back from the web server. Page level concurrency (C) improves on this by having multiple web pages be fetched concurrencly, but still suffers from the same idle wait problems as it iteratively fetches the resources.
Resource level concurrency (R) tries to fix this by having as much of the resources be fetched concurrently as possible, but limiting the global concurrency level of the fetch to avoid having an un-bounded system. While better that (C), it does have one small problem, which is that for a given a host, it might open a lot of concurrent requests. It is not un-common for rich web pages to have as much as 50 or 60 references to resources and in this model, it is possible that all of them are being fetched concurrently if the pool is large enough. At scale this can lead to exhaustion of server side resources.
Host level concurrency (H) finally tries to address this problem by bonding concurrency at the host level, but having as much of the hosts run concurrently as possible. This has one other advantages in addition to bounding resource utilization on the server side, which is that, with HTTPS, every connection has a large overhead with respect to the connection setup with the SSL handshake. So bounding the concurrency level, also has the added advantage of being able to reuse a few keep-alive connections per host that are kept connected across requests so as to minimize the amount of connection setup and SSL handshake cost. Interesting, most browsers I believe work this way, bounding concurrency at the host level, for similar reasons, which is why you also see websites doing things like domain sharding to maximize the number of concurrent connections from browsers to their domains, thus allowing sites to be loaded faster.
Code
Now let’s take a look at the code. We first start with the definition of a resource as
something that has a URL and a type, along with around it’s size, time taken to fetch it
and any errors once resolved. Every resource, more importantly, defines a get operation
that can be called once constructed to resolve it by fetching the resource after it is
constructed.
type resourceType int
const (
notRemoteResource resourceType = iota
htmlResource
cssResource
scriptResource
imageResource
)
type resource struct {
resType resourceType
url string
size int
err error
timeTaken time.Duration
}
func (r *resource) get() ([]byte, error) {
// ... implementation ....
}
We then build on top of this by defining a page as containing a base resource representing the HTML web page and a collection of resources within it, called assets, once we fetch the page and parse it. We also track the time taken and total size etc as part of the same structure as part of resolving the page.
type page struct {
url *url.URL
base *resource
assets map[resourceType]map[string]*resource
total int
timeTaken time.Duration
parseTime time.Duration
err error
}
If we notice, assets is defined as a map of resource type to another map of string’s to resources. The idea here is that, a given web page might refer to the same resource multiple times, like image references, and with things like caching behavior etc, we want to resolve each resource only once. So by having the value as a map of string to resource, where the string represents the resource URL, we can automatically de-dupe the list of unique resources at parse time.
Given these base data structures, the operation we want to perform is, given a list of URLs,
we want to get a list of resolved page references back. Or in other words, the main operation
has the function signatures func (urls []string) []*page.
As we get into concurrency, Go defines the following four main ideas to support it:
- A concept of a channel. One creates a channel by calling
make(chan type)where type is the type of data to be sent on the channel. So to create a channel to send integers on, one would saymake(chan int) - A way to send data over the channel by using the
<-operator on the right side of a channel. So for example, if we have a channelcfor sending integers and an integer valuei, we can sendiover the channelcby sayingc <- i - A way to receive data from a channel by using the
<-operator on the left side of a channel. So for example, we have a channelcfor receiving integers from, we can receive a new value into the variableiby sayingi = <-c. Since channels can be closed, and as go supports multi-value returns, one way to determine if we have a valid read is to not only read the value, but also a boolean variable along with it, like so,i, ok := <-cand then checking ifokis true. [Note: In Go, the:=operator is used to both declare and define the value of new variables, while=is used to assign values to existing variable.] - A way to spawn new go routines given a function using the
gokeyword. So if we have a functionf, we can run it concurrently in go by sayinggo f().
Let’s now look at the implementation of each of the models.
Synchronous
Let’s start with the synchronous model, which constructs a page out of each URL and then calls
resolve() on it to get the details. Once we are done looping through the urls, we return
the accumulated results.
func resolveSynchronously(urls []string) []*page {
pages := []*page{}
for _, url := range urls {
p, err := newPage(url)
if err != nil {
log.Printf("Error constructing page: %v", err)
continue
}
if err := p.resolve(); err != nil {
log.Printf("Error resolving page: %v", err)
}
pages = append(pages, p)
}
return pages
}
func (p *page) resolve() error {
startTime := time.Now()
defer func() {
p.timeTaken = time.Since(startTime)
}()
body, err := p.base.get()
if err != nil {
return err
}
p.total += p.base.size
if err := p.parseResources(body); err != nil {
return err
}
return p.resolveResources()
}
func (p *page) resolveResources() error {
for _, a := range p.assets {
for _, r := range a {
if _, err := r.get(); err == nil {
p.total += r.size
}
}
}
return nil
}
Page Level Concurrency
To implement page level concurrency, we just need to make sure that resolve on each page
can happen within it’s own go routine. In addition, once we are done resolving each page,
we also a need a way to get the results back so that they can be collated together. We can
do this by defining a function that given a channel to send page’s on and a page, first
resolves the page and once done, sends it over the channel. The main routine then just
defines a channel for the pages, spawns this function as a go routine per page, along with
the channel and then reads results off this channel to get back all the resolved pages,
like so
func resolvePage(result chan<- *page, p *page) {
p.resolve()
result <- p
}
func resolveInGoRoutine(urls []string) []*page {
pages := []*page{}
results := make(chan *page)
numPages := 0
for _, url := range urls {
p, err := newPage(url)
if err != nil {
log.Printf("Error constructing page: %v", err)
continue
}
numPages++
go resolvePage(results, p)
}
for i := 0; i < numPages; i++ {
if p, ok := <-results; ok {
pages = append(pages, p)
}
}
return pages
}
as can be seen, most of the functionality for resolve etc., as defined above is re-used and we can just concentrate on the concurrecy aspects here.
Resource Level Concurrency
In order to support resource level concurrency, we have to do some deeper surgery. We first have to support the notion of resolving the page concurrently at the page level. What we want here is to have a pool of workers, and for each resource, the page should delegate the work of resolving that resource to the pool in a concurrent manner. We also want to abstract away the notion of what kind of pool we are using and in Go, we do that by using a channel.
Let’s start with a definition of a channel for these requests. Given that requests can happen from multiple go routines and we need a way to send back the result to the originator. Again, using channels, we can define a request as having a resource and a channel to send the result back on. The result itself is defined as containing the resolved resource, the body that was fetched (as we need it during the initial page resolution to parse the HTML) and any errors that might have occured during the fetch.
type request struct {
res *resource
resp chan<- *result
}
type result struct {
res *resource
body []byte
err error
}
We then define a worker function that given a request channel, keeps reading off it to get the next request to process, fetches the resource and then sends the results back on the embedded results channel.
func worker(reqChan <-chan *request) {
for {
if r, ok := <-reqChan; ok {
body, err := r.res.get()
r.resp <- &result{res: r.res, body: body, err: err}
}
}
}
Using these primitives, we can then define a resolveConcurrently operation the page
object that given a request channel and a page channel, uses the request channel to
resolve the resources and then send the result back, once resolved over the page channel.
The page channel is used so that each page can run concurrently in it’s own go routine.
In order to resolve concurrently, we first create one result channel to resolve the main page, read the result from it and then create a new buffered results channel to resolve each of the parsed resources. Channels by default are not buffered in go and trying to send on it will block unless there is a receiver to read from it. So it can also be used as a synchronization point between the go routines. But in this case, since we are staging all the requests first before reading the results, it can block the system, unless we buffer it as noted in the code comments below:
func (p *page) resolveConcurrently(reqChan chan<- *request, pagesChan chan<- *page) {
startTime := time.Now()
defer func() {
p.timeTaken = time.Since(startTime)
}()
pageRespChan := make(chan *result)
reqChan <- &request{res: p.base, resp: pageRespChan}
resp := <-pageRespChan
if resp.err != nil {
p.err = resp.err
pagesChan <- p
return
}
if err := p.parseResources(resp.body); err != nil {
p.err = err
pagesChan <- p
return
}
p.total += p.base.size
p.resolveResourcesConcurrently(reqChan)
pagesChan <- p
}
func (p *page) resolveResourcesConcurrently(reqChan chan<- *request) {
// we create a buffered channel to receives the results from, with
// the buffer size set to the number of resources to fetch. This is
// important because the send reqChan is not assumed to be buffered,
// this is routine first queues all the requests before starting
// to read the response. Having the result channel buffered means
// that the worker threads on reqChan will also be able to send a
// result even if the reader is not ready, thus avoiding blocking
// the workers. Consider the degenerate case of having only one
// worker go routine receiving on reqChan. Without this buffer,
// the whole process could hang, with writes blocked on reqChan
// and the result chan.
nResources := p.numResources()
resourcesChan := make(chan *result, nResources)
for _, a := range p.assets {
for _, r := range a {
reqChan <- &request{res: r, resp: resourcesChan}
}
}
for i := 0; i < nResources; i++ {
resp := <-resourcesChan
p.total += resp.res.size
}
}
Building on these primitives, we can finally define resource level concurrency as first creating a request channel and spawing a pool of workers to listen for resource requests. We then use this to spawn each page in it’s own go routine, passing it the request channel. This in turn is used along with a new channel for getting resolved page results from, as in the case of host level concurrency, to resolve each page concurrently in it’s own go routine.
func resolveConcurrently(urls []string, nPoolSize int) []*page {
reqChan := make(chan *request)
// create pool of workers
for i := 0; i < nPoolSize; i++ {
go worker(reqChan)
}
return doConcurrently(reqChan, urls)
}
func doConcurrently(reqChan chan<- *request, urls []string) []*page {
pages := []*page{}
pagesChan := make(chan *page)
numPages := 0
for _, url := range urls {
p, err := newPage(url)
if err != nil {
log.Printf("Error constructing page: %v", err)
continue
}
numPages++
go p.resolveConcurrently(reqChan, pagesChan)
}
for i := 0; i < numPages; i++ {
if p, ok := <-pagesChan; ok {
pages = append(pages, p)
}
}
return pages
}
Host Level Concurrency
Finally, to build host level concurrency, we just need to change the behavior of the pool such that each request is routed to a pool maintained per host instead of one global worker pool as above. We can do this quite easily by introducing a go routine that maintains a map of hosts to a request channel that is backed by a pool of workers. We can lazily create this channel and it’s pool as we see each new host. Modifications to this map are inherently safe as they are internal to and accessed only by this routine. The go rotine takes one request channel as input to read from for new resource requests and routes it to the appropriate host based pool by writing to that pool’s channel. The rest of the system can stay exactly the same, with the difference that they are now given a channel to the router instead of directly to the pool. So the addition code needed is just:
func routeByHost(reqChan <-chan *request, nPoolSize int) {
byHost := map[string]chan *request{}
for {
if r, ok := <-reqChan; ok {
host := r.res.host()
if _, found := byHost[host]; !found {
c := make(chan *request)
byHost[host] = c
for i := 0; i < nPoolSize; i++ {
go worker(c)
}
}
byHost[host] <- r
}
}
}
func resolveConcurrentlyByHost(urls []string, nPoolSize int) []*page {
reqChan := make(chan *request)
go routeByHost(reqChan, nPoolSize)
return doConcurrently(reqChan, urls)
}
Observations
As can be seen above, thinking about concurrency using channels, “the means of communication”, provides for a lot of flexibility in being able to compose different models of execution, while abstracting away the actual implementation from the caller and the callee. But in order for this to work efficiently, and at scale, there needs to be a ground up support at the language level to suspend and resume these concurrent processes, without tying up the native OS level thread. It is quite reasonable to think about a problem having thousands of go routines at runtime in go, while spawing the same number of native threads would not be practical or feasible. See this faq entry for example of what is meant by a goroutine.
Again, the complete code is available at https://github.com/satyasm/gopagesize . Let me leave you with one final interesting question though. We have seen how to reason about and implement the concurrency aspects of the code here. But how would you reason about the performance characterstics of this code? What determines performance here? :-)