Opinionated view of a 3rd generation serving framework
Or how to get 1 second render times on complex web pages …
In the previous post, we saw how we could classify internet serving architecture into different generations and what the implications of each generation are. We also observed there, how, as we enter 3rd generation and later, the need for concurrency becomes central to having a performant serving system.
In the world of complex web pages, like YouTube, etc., the question then arises on how to organize the code to balance ease of coding while still retaining the performance benefits. In this post we look at one such idea, which has proven to work well in practice.
Problem Definition
What do we mean by 1 second render time? It means that once the user types in the URL, the web page is visible for the user to interact with within or at 1 second. There is a lot of content in the web today, like this blog post or this book or this Google developer documentation that talk about browser page rendering and how to look at it from a front-end perspective.
But I’ve rarely seen folks talk about what it means from a backend web-server perspective on how to generate and organize the content in the first place.
Let’s start by quantifying the problem.
Modern browsers today implicitly support what is called the Navigation Timings API in JavaScript to capture and expose the performance of a given web page load. The excellent Navigation Timing Bookmarklet project provides a bookmarklet that you can drag into your bookmark toolbar and once a page is loaded, click to visualize the various stages at a high level.
Here for example is how one of the page loads on the current blog looks like:
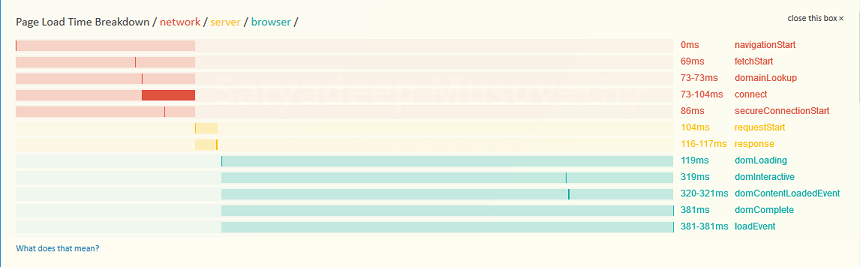
As one can see, the whole of the page load can be considered as being three distinct phases, namely,
- Connect: which include the DNS lookup, TCP connection and SSL handshake for HTTPS. This is the red colored data in the rendering.
- Request: which is when the actual “GET /….” part is sent to the web-server for fetching the content. This is the yellow colored data in the rendering.
- Render: which includes the parsing of the HTML received, generating the DOM, fetching any addition resources referenced in the HTML, like CSS, script and IMG tags and rendering the page on the browser. This is the blue colored data in the rendering.
Most of the documentation, like the ones references above concentrate on how to organize the HTML content so as to reduce the time in the Render phase. In this post, we will take a stab at the Request phase, or in other words, how to structure the code in the backend so as to make the combination of \( Connect + Request + Render \) is 1 second or lower.
The rendering above is quite generous as we are using a 5th generation architecture, which means we are mostly serving a static page and connecting from within the US.
The Connect phase is mostly driven by network latency and DNS lookup timings. If you look at data from AT&T and Verizon , it ranges between 30 to 50 ms for roundtrip within the continental US and about 100 ms to cross the atlantic. So the rule of thumb is to assume between 250 to 300 ms for connection setup, assuming international traffic and SSL handshake time.
Similarly, assuming we do all the “right” things for the Render phase to include caching and edge-servers for serving the various assets, including JavaScript startup time and DOM rendering time, we can assume between 300 to 400 ms for the browser to start rendering the page and make it visible to the user after fetching the content.
Assuming around 100 ms for the latency bandwidth, to be perfectly safe, we are looking at a Request time between 250 to 300 ms to generate the web page.
Approach
Assuming a 3rd generation or later architecture, rendering the HTML content for the web-page will consist of again three phases,
- Parsing the request to find out what resources, along with their parameters have to be fetched in order to render the page.
- Fetching the data from the resources
- Generating the HTML containing the data fetched from the various resources.
Going back to the YouTube example, if we consider it being made of three main sections, namely, the header, left-nav and the central stream, we can imagine that there could be three services, one for each of the sections respectively. The problem we face though is that HTML has no concept of these sections or components. So have an impedance mismatch between how we would like to think about the page vs how the HTML document wants it to be described.
We first need to address this problem.
One of the most elegant solutions that exist out there to address this problem is using the concept of a Widget from the Yesod Haskell Web Framework. We can visualize the concept of a widget as an interface that supports getting the various parts of the web page so that they can be stitched together correctly by a higher level orchestrator. For example, in Go, it could look something like
type Widget interface {
// header information
getCss() []string // CSS file links
getJsSrc() []string // JS script source links
getHeaderContent() []string // other header content like inline CSS, script, meta-tags, etc.
getTitle() string // (optional) only if this widget is providing the title
// body information
getBody() string // body content
getBodyScripts() []string // any scripts that need to be added at the end of the body
}
or in Java as
public interface Widget {
// header information
public List<String> getCss(); // CSS file links
public List<String> getJsSrc(); // JS script source links
public List<String> getHeaderContent(); // other header content like inline CSS, script,
// meta-tags, etc.
public String getTitle(); // (optional) only if this widget is providing
// the title
// body information
public String getBody(); // body content
public List<String> getBodyScripts(); // any scripts that need to be added at the end of
// the body
}
This then allows the main driver of the framework, after parsing the request, identify the list of widgets that need to make the current page and then call the appropriate functions during the generation phase to stitch together the HTML in the right format.
This also then allows the framework to do optimizations like early flush once all the header information is available to further improve the perceived performance of the web page.
While this solves the impedance mismatch problem, it does not address the performance concerns for generating the HTML. Assuming we budget around 50 ms for the \( Parse + Generate \) phases (which is not unreasonable as they are mostly doing in-memory computations based on local data), we are left with around 200 ms for fetching the resources.
Assuming we have to fetch say 5 resources to fetch the page (I know we said three above, but bear with me as an illustration - it can get to larger numbers if we consider each itself being made of additional widgets - yes it’s turtles all the way down), assuming a budget of 200 ms, assuming sequential fetch of each of these resources will mean that the mean latency for each resource cannot be more than 40 ms ( \(200 \div 5\) ).
On the other hand, if we were to concurrently fetch each of these resources, then the budget increases to 200 ms for each resource! It’s far easier to build resources that have to return data in 200 ms than ones that have to do it in 40 or 50 ms. In addition, the concurrent fetch also has the benefit that as the number of resources needing to be fetched increases, it latency budget per resource does not drop significantly, whereas in the sequential case, it changes drasticaly for each additional resource added to the mix.
So, can we have our cake and eat it too? Meaning, can we solve the performance problemn and the impedance mismatch problem? Turns out we can! To do so, let’s enhance the Widget specification with two additional methods, one to get the list of resource URLs to fetch for rendering the header content and another to get the list of resource URLs to fetch for rendering the body, like so,
type Widget interface {
// definitions as above ...
getHeaderResourceUrls() []string // list of url's to fetch for rendering the header
setHeaderDataReceived(data *ResourceData) // data fetched for header resource URLs
getBodyResourceUrls() []string // list of url's to fetch for rendering the body
setBodyDataReceived(data *ResourceData) // data fetched for body resource URLs
}
public interface Widget {
// definitions as above ...
List<String> getHeaderResourceUrls(); // list of url's to fetch for rendering the header
void setHeaderDataReceived(ResourceData data); // data fetched for header resource URLs
List<String> getBodyResourceUrls(); // list of url's to fetch for rendering the body
void setBodyDataReceived(ResourceData data); // data fetched for body resource URLs
}
Here ResourceData represents the results of doing the concurrent fetch. Now the widgets just declare what resources need to be fetched. The orchestrator can then collect all this information by querying the widget, dedup them, and then make one concurrent fetch of all these resources. Once the data is available the appropriate set method is called so that widgets can update their local state and render the appropriate content for each of the generation phases.
Why two get/set combinations? In practice it turns out that we either need some data to be able to render personalized content in the header section (like title etc.,) or need to first do a setup like call to get some meta-data before doing the actual request during the body phase. Splitting it into to and then providing a budget of 50 ms for the header resources and 150 ms for the body resources still allows us to provide adequate budgets for a quick header flush, followed by a more generous body content generation.
Finally, the psuedo-code for the orchestrator itself now becomes
build list of widgets given current request
collect all resource requests for HTML head content
fetch resources concurrently
render the HTML head content with early flush
collect all resource requests for HTML body content
fetch resources concurrently
render the HTML body content
The nice thing is that this micro-framework idea can be implemented in almost any language, including PHP (for example using the curl multiget for the concurrent fetch). And it allows the rest of the system to have generous budgets, while still controlling the overall render time performance for the HTML on the server side.
The render phases can mostly be syncrhonous as they are compute bound and working on local data. This leads to, what is computer science, we call high cohesion, but low coupling between the widgets. Each widget or component author can work fairly independently of others, which also leads to better maintainence and easier evolution of the web page as the requirements change.
Observations
While algorithmic complexity (and Big-O notation) are useful to describe and reason about the runtime characteristics of code at the small scale, performance in today’s systems is mostly governed by I/O latency. As computers have evolved, memory and I/O access speeds have not kept up with processor speeds. So most CPU’s spend a lot of idle time waiting for data. This requires us to think differently on how to attain “global optima” of performance by factoring in the I/O cost. As can be seen above, doing so does not have to mean sacrificing code maintainabilty or structure. Instead, we can use separation of concerns to solve for each using the appropriate tools, while still leaving most of the code synchronous and easy to reason about.