Evolution of Internet serving architectures
In the previous two blog posts, we looked at a simple example for asynchronously and concurrently fetching resources from the internet, first in Go , and then in Java. The solutions were useful as a means to to explore the different ways of approaching and reasoning about concurrency, based on each languages strengths. But if we were to take a step back and look at how web serving architectures and web page rendering having evolved over the past decades, it turns out that the problem itself is far more interesting…
This post explores why that might be so.
Architecture Generations
If we were to take a step back and look at how the web have evolved over the past decades, not from the perspective of the kinds of content, like the use of images, videos etc., but from the complexity and richness of the content mix, we can potentially classify web serving architectures into different generations.
To concretize what we mean by “richness of content”, let’s consider YouTube . The home page if one looks at it, consists of three major sections, namely the header which contains the logo, search box, account management (login status), notifications, ability to upload videos etc. Essentially interactions that are site wide. Then we have the left navigation bar, that are current site specific navigation links to different groupings of content within the site, like your history, subscriptions etc.,. Finally we have the central area which consists of recommendations to videos based on content popularity and user preferences. This is what we mean by the richness of information, namely, the different categories of information that are merged together to make a modern web page.
Contrast that to the very first web page , which was just a document with a collection of links.
From this perspective, we can classify the internet serving architectures as broadly belonging to five generations as follows:
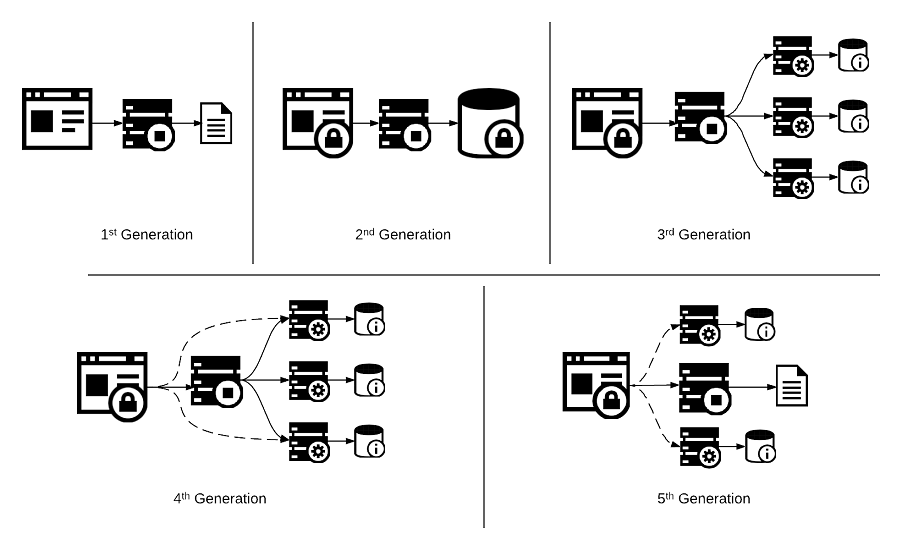
First Generation
The first generation of serving can be visualized as a “document server” which was mainly responsible for servings files of a simple storage system, like a file-server or a directory in the file system. This lead to the rise of simple web servers like Apache “a patchy web server” and others. When the need arose for adding more dynamic content, it lead to the creation of techniques like Server Side Includes which allowed for simple mixing of content while generating the final document.
This technique has proven to be useful enough, that it still exists today in the form of Edge Side Includes where the content is mixed in from resources rather than just files, within various edge servers.
The design forces at play here can be summarized as:
| Motivation | Tradeoff |
|---|---|
| Serve web documents at scale, with some dynamic content mixed in | Limited flexibility in kinds of dynamism supported, but simple to use with little to no coding needed |
Second Generation
As the need for more granular content rose, it became clear that generating the HTML for every page upfront is both impractical and wasteful. The quintessential use case for this were online email clients.
For example, when you have something like the Linux Kernel Mailing List (lkml), where each message is it’s own page , then it is not practical to be able to have all the HTML for all the mail messages generated and all the time, as most views of pages will be only for a short time and thus the subset of “active pages”, among all the available pages will be a tiny fraction.
But at the same time, we need to be able to render any page “on demand”.
This lead to two things:
- The need to run code as part of the web page generation, leading to the invention of things like the Common Gateway Interface - CGI as a way for the webserver to be able to call out to arbitrary programs to generate the pages, followed by the Fast CGI protocol once people realized that it’s costly to spawn a new process for every request.
- The storage of the information in a “database” and then having the code fetch the data to generate the HTML at request time.
This was the era for the prevelance of perl as the scripting language of choice to write these CGI programs, leading to the invention of PHP, which flipped the programming model from code generating HTML to having code embedded in HTML like templates. The evolution of this style of web page generation, culminated with the release of Ruby On Rails.
Here is where we first see the rise of dynamic or scripting language in web page generation. It turns out that building web pages is a very visual activity, and having a quick edit-view cycle makes a huge difference in productivity. This need was so strongly recognized that Java introduced that concept of Java Server Pages - JSP and Microsoft introduced (Active Server Pages - ASP)[https://msdn.microsoft.com/en-us/library/aa286483.aspx] to support this model.
Each of these inventions, in addition to changing the way the pages are built, also brought out some very interesting ideas around web page generation. PHP’s shared nothing execution model, for example, where every request is a fresh slate, makes programming and reasoning about the code very very simple and easy to get right. Here is a presentation of Yahoo adopting and using PHP. The value of this execution model has largely not been recognized as one of the main reasons for the “ease of use” of PHP and why it was simple for early web hosting companies to start offering hosted PHP sites.
Ruby On Rails on the other hand introduced the concept of “structure” and convention-over-configuration as a way to organize and layout the server side code so that default decisions around URL request parsing etc., can be automated away. This influence has been so strong that most web frameworks post Ruby On Rails have built on this kind of a structure.
But with the introduction of “running code to generate the web page”, we also entered the era of “security bugs”, with the most well known being the infamous SQL Injection attacks.
This is the generation where we transition from “web pages” to “websites” and the standardization of the three tier architecture as one of the gold stardards for building web servers.
The design forces at play here can be summarized as:
| Montivation | Tradeoff |
| Dynamically generate HTML to improve efficiency of serving - websites instead of web pages | Everything needs to fit in the 3-tier architecture model, with most data being in some form of relational database. Performance is governed by the performance of the DB. |
Third Generation
As the complexity and volume of information being presented started to increase, it was found that the “one ring to rule them all” model of putting data in the DB had distinct limitations. For example, databases tend to be scaled vertically, while web servers can be scaled horizontally. Vertical scaling it turns out is not only costly but also has inherent limits. It is quite normal that web pages have a very high skew in number of requests by time of day or larger time windows. This paper for example shows typical patterns in large scale websites.
So in order to be able to handle this, it became necessary to scale out the database for “peak loads”, which meant that most of the resources (and costs) are heavily under utilized during normal hours. The simplest way to solve this was to “divide and conquer” and separate the data for each of the subsets of information into it’s own services. The web server would then “scatter/gather” for a given request across these services to build the final page. Looking back to our YouTube example earlier, we could say have a service that managed the information in the header, another for the left rail and a third one for the central recommendations.
Each of these services could then use their own database and can be optimized independently for performance, by say, using different caching caching strategies for their content. Here is when we see the start of prevalence of key-value stores like Redis and Cassandra among others as backing stores for these services.
But the introduction of multiple services, at scale, brought out a different performance concern. The naive implementation of sequentially calling each of the services to get the data leads to a performance profile as follows:
$$ Page\_Time = Parse\_Time + \sum_{r=1}^{n} Resource\_Time + Render\_Time $$
This if each request takes 100ms and we have 5 requests, then we end up with 500 ms just to fetch the data. This is obviously bad. The way to address this problem then turns out to call each of these requests concurrently, so that instead of the sum of all requests, we end up with just the max time for the slowest request or in other words
$$ Page\_Time = Parse\_Time + \max_{r=1}^{n} ( Resource\_Time ) + Render\_Time $$
This is where concurrency starts becoming important and fundamental to building performant web servers. This is the era when we see the introduction of asynchronous scalable web servers like NGINX that are built ground up assuming asynchronous communication.
As JavaScript starts getting more powerful, we also start to see the use of techniques like PJAX to avoid re-rendering the whole page as subsets of the pages change on user interaction. In this model the HTML is still rendered on the server side, but dynamically replaced on the client by fetching the subsets of the page for the changes.
The design forces at play here can be summarized as:
| Motivation | Tradeoff |
| Scale the composition of information in websites, while reducing total cost of infrastructure | Additional complexity around page rendering and request lifecycle management, i.e., necessity to solve for concurrency to gain the performance at the cost of infrastructure management. |
Fourth Generation
The fourth generation can be thought of as replacing PJAX with client side rendering by manipulating the Document Object Model after fetching the data from the services. Here the initial HTML is still rendered on the client, but small changes to the site, like adding a comment etc.,. are handled by sending the new data to the appropriate services directly from the browser and then adding the new content as elements under the DOM.
This evolution also leads to the adoption of technologies like reverse proxies so that different services can be made to appear like they existing under the same origin server from the URI namespace perspective to the browsers.
The design forces at play here can be summarized as:
| Motivation | Tradeoff |
| Minimize perceived latency of interaction for end-users | Duplication of logic and more client side DOM manipulation. |
Fifth Generation
The fifth generation takes the fourth to it’s logical conclusion, wherein all dynamic rendering happens on the client side. The browser evolves from being used as a document rendering engine to an application delivery platform. This evolution sees the rise of Single Page Application - SPA and frameworks like ReactJS, EmberJS among others that make the manipulation of performance of rendering the DOM cheaper and easier and also the rise of “compile-to-JS” languages like Elm which are pure functional, complete client side execution environments.
So at the time of the request, the webserver mostly sends down a static HTML and references to javascript code for all the dynamic behavior.
From this lens, this blog for example, can be considered as a fifth generation architecture by accident and necessity! The core of the content in the blog is generated using Jekyll and rendered to HTML. The commenting and math display capabilities are loaded in client side using JavaScript using Disqus and MathJax respectively. No code runs in the server for rendering the basic page. It’s just a file on the file-system ( hosted by GitHub ).
In the fifth generation architecture, the concurrency concerns are pushed all the way upstream to the browser!! It has also meant that we are not looking at very large JavaScript code bases, which in turn has lead to the invention and adoption of more “type checking systems”, like Typescript that can detect and help developers resolve more issues at coding / compile time. Like the SQL injection bug for security, the quintessential representation of this problem is the infamous “undefined is not a function” .
The design forces at play here can be summarized as:
| Motivation | Tradeoff |
| Don’t duplicate logic between the client and server, make it client only, to retain perceived latency benefits | Cost of initial load time and complexity of client side code interactions. |
Observations
As can be seen in this semi-historical perspective, as we approach and go beyond the 3rd generation architectures, solving for concurrency becomes one of the central problems of building performant web servers. But at the same time, we must take care to not interpret this description as any kind of qualitative statement on the different between the different generations. A fifth generation architecture is not necessarily better than a third generation one. Rather it’s a question of “horses for courses”. Each architecture solves for certain needs but also brings it’s own complexity. So for example, small internal websites, with low traffic, that manage simple data sources might be better built using 2nd generation architectures. It’s a question of identifying what the tradeoff’s are and whether the cost is worth the tradeoff in choosing a particular generation.