Concurrency in practice - Java
Java
unlike Go, focuses on the values being produced as the main fulcrum for organizing and scheduling
concurrent and asynchronous tasks. Java 8 introduces the concept of a
CompletableFuture
as a way to compose these values together using a
ForkJoinPool
for running the actual computations. Further the introduction of
lambda expressions has made it
easy to represent the code for these transformations succinctly. This makes it easy to see the “flow” of
the computations / transformations independent of the actual worked performed at each step.
In this post we will look at a small I/O intesive problem and one possible way we could use these capabilities and to reason about and chain these asynchronous concurrent operations using Java 8.The complete code is available on GitHub at satyasm/JavaPageSize and can be built using maven as documented in the README.md on the project.
Problem Definition
Say, we have a list of webpage URLs, and we want to find out what the size of the webpage is.
We can define the size of the webpage as the size of the original HTML for the page, along with
the size of all the assets it references, namely, css, image and js files in link, img and
script tags respectively. So the idea is that given a webpage URL, fetch the page, parse the
HTML to find the unique references as above, download those resources and finally sum the total size of
the bytes received to get the total page weight.
We can visualize one possible approach to this problem as follows:
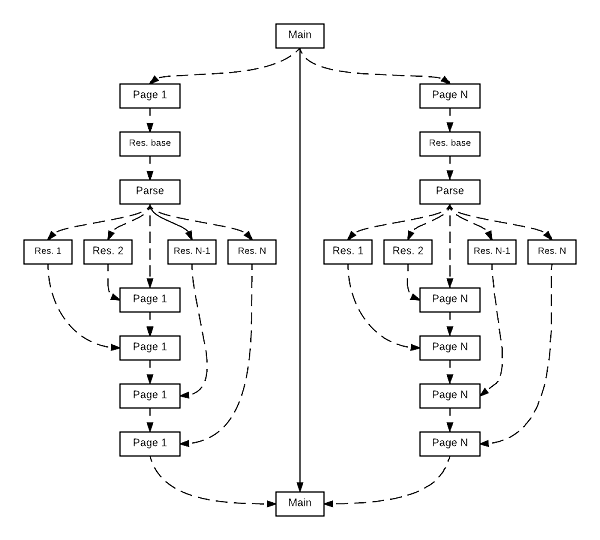
For every web-page given, we start an asynchronous computation. The main thread, having “forked” all the pages, then just waits for them to complete, collects and prints the results. Each page in turn starts with the base page URL and starts an asynchronous computation to fetch the HTML. Once the HTML is fetched, it is parsed and for each of the resources found, a new request is “forked” asynchronously.
The important question now becomes how do we get the results from these resources. We can do the same thing we did for the pages, which is maintain a list of all the outstanding resource get’s and then wait for all of them to complete before consolidating the results. We can also take another approach. We can “chain” the consolidation. So, for every asynchronous resource fetch we initiate, we can tag on a follow up computation using the thenCombine method which can be used to “join” two CompletableFuture’s into another CompletableFuture that is produced with both of them complete.
The main advantage of this approach, is that we avoid “blocking” the page thread that spawned the resource fetches. This is important, because unlike in Go, where each go routine is very cheap and supports language level suspend and resume, the computations in Java are scheduled on OS level threads. So anytime we do a join or get operation, we effectivly block the current thread till all the sub-operations have completed (or in other words we are back to the synchronous world, which we want to avoid). Each resource we fetch is then combined with the page asynchronously to finally produce a new CompletableFuture that represents the state of computation once all the resources have completed successfully.
When working with Future’s and values, this style of “fork-join” thinking starts to get quite prevelant and in fact there is a reason that the default underlying thread pool used for scheduling these compositions is called a ForkJoinPool . :-)
Code
In order to fetch the web resources asynchronously, we use the popular AsyncHttpClient library. This library, built on top of Netty uses the java.nio to perform asynchronous network I/O, while providing a higher level interface that is more appropriate for HTTP client interactions. I has built in connection pooling and re-use capabilities, which are useful with HTTPS connections, as the connection overhead for each new connection can be quite large.
For parsing and traversing the HTML fetched, we also use the popular jsoup library.
Now let’s look at how the above model get’s represented in actual code. We start with the main Application class that spawns off the computations.
package org.satyadeep.javapagesize;
// ... imports ...
public class Application {
public static void main(String[] args) throws ExecutionException, InterruptedException, IOException {
List<String> urls = loadUrlsFromArgs(args);
try (final AsyncHttpClient asyncHttpClient = new DefaultAsyncHttpClient()) {
final long startTime = System.currentTimeMillis();
List<CompletableFuture<Stat>> stats = new ArrayList<>();
// first off each page asynchronously
for (String url : urls) {
stats.add(new Page(asyncHttpClient, url).resolve().thenApply(p -> p.getStats()));
}
// wait for get's to complete
CompletableFuture.allOf(stats.toArray(new CompletableFuture[0])).join();
Stat.headerToStdout();
for (CompletableFuture<Stat> s : stats) {
s.get().toStdout();
System.out.println();
}
System.out.printf("Total time: %d ms", System.currentTimeMillis() - startTime);
}
System.exit(0);
}
// ... implementation details ....
}
We use try-with-resources syntax to create an instance of AutoCloseable AsyncHttpClient instance. This is then used to fork off each of the pages and once each page is done, we then chain a computation using lambda syntax to extract the statistics for that page. We then block the main thread waiting for all the pages to complete and once done, extract and print the statistics. In this case, it is ok to block the main thread, as that is the intent of the program (to wait for all the results to come back).
The page resolution in turn starts by doing a fetch of the base URL resource, and chains a computation to parse, extract resource references from the fetched HTML and asynchronously fetch and combine the resource references.
package org.satyadeep.javapagesize;
public class Page {
// ... member variables ...
public Page(AsyncHttpClient asyncHttpClient, String url) {
this.asyncHttpClient = asyncHttpClient;
this.base = new Resource(asyncHttpClient, url, ResourceType.HTML);
}
public CompletableFuture<Page> resolve() {
final long startTime = System.currentTimeMillis();
CompletableFuture<Page> pageF = this.base.get().thenApplyAsync(rr -> {
if (rr.resource.getError() != null) {
return this;
}
this.size += rr.resource.getSize();
this.loadResources(rr.response.getResponseBodyAsStream());
return this;
});
return loadAssetsAsync(pageF, startTime);
}
private CompletableFuture<Page> loadAssetsAsync(CompletableFuture<Page> pageF, final long startTime) {
return pageF.thenCompose(p -> {
CompletableFuture<Page> result = CompletableFuture.completedFuture(p);
for (Map<String, Resource> resByUrl : p.assets.values()) {
for (Resource res : resByUrl.values()) {
result = res.get().thenCombine(result, (rr, p1) -> {
p1.size += rr.resource.getSize();
return p1;
});
}
}
return result;
}).thenApply(p -> {
p.timeTakenInMillis = System.currentTimeMillis() - startTime;
return p;
});
}
// ... implementation details ...
}
To understand this, let’s start with the definition of what a Resource is. A resource represents a URL and supports a get operation which asynchronously returns a ResourceResponse, containing the updated resource and the AsyncHttpClient Response object from the fetch.
package org.satyadeep.javapagesize;
public class Resource {
public static enum ResourceType {
HTML, CSS, IMG, SCRIPT
}
// ... member variables ...
public Resource(AsyncHttpClient httpClient, String url, ResourceType resType) {
this.resType = resType;
this.asyncHttpClient = httpClient;
this.url = url;
this.error = null;
}
public CompletableFuture<ResourceResponse> get() {
final long startTime = System.currentTimeMillis();
try {
return asyncHttpClient.prepareGet(url).setFollowRedirect(true).execute().toCompletableFuture()
.thenApplyAsync(resp -> {
this.timeTakenInMillis = System.currentTimeMillis() - startTime;
this.size = resp.getResponseBodyAsBytes().length;
return new ResourceResponse(this, resp);
}).exceptionally(err -> {
this.error = err;
return new ResourceResponse(this, null);
});
} catch (Exception e) {
this.error = e;
return CompletableFuture.completedFuture(new ResourceResponse(this, null));
}
}
public static class ResourceResponse {
public final Resource resource;
public final Response response;
public ResourceResponse(Resource resource, Response response) {
this.resource = resource;
this.response = response;
}
}
// ... implementation details ...
}
The important insight here is to note what happens when exceptions occur. There are two possible places that can throw an exception, when preparing the get operation or during the actual fetch due to things like connection reset or timeout (say you lost wifi…) etc.,. We want to handle both these cases.
By default, chains of asynchronous computations “fail fast”. Which means that if a particular step ends up throwing an exception, then all the subsequent operations are abandoned and the top level join or get will basically throw the exception that caused the chain to break. Since we are representing the combination of all the resource get’s as a chain or asynchronous computation, this is bad, because it means that if even if any one resource fails, all the other resource results will be abandoned and the top level results will not have their sizes.
We want to avoid that.
One simple way to do that is to trap these exceptions at the get level and then enter the asynchronous space by produce the results of the expected type. In the case the exception occurs during the fetch, since we are already in the async space, we can do so by using the exceptionally method to squirrel away the exception inside the resource as an error and return a ResourceResponse with a null response.
In case the prepareGet itself fails, since we are not yet in the asynchronous space, we need to enter it as the return type of the function is an CompletableFuture. Again, we can do so using the CompletableFuture’s static completedFuture method. the important thing to remember here is that, in this case, we are still in the calling routine’s thread context…
With this context (pun intended), going back the Page implementation, we can now see, that we first do a get on the base resource, which returns a ResourceResponse. We aynchronously chain an operation (thus switching context in all cases to the ForkJoinPool.commonPool() thread pool), to look at the result. If the error in the response is not null, we fail fast on the computation and just return the page object. Otherwise, we parse the HTML and for the resources extracted, chain the get computations.
The chaining of the results can be seen in the loadAssetsAsync method. Here again we start with the current Page, raised to the asynchronous space using the completedFuture static method. Then for each resource extract, we fork off a get and chain it with the asynchronous Page value, so that when the get completes, we can cumulative sum the resource sizes. We remember the result of this composition as the current CompletableFuture for the page, which then get’s used for the next resource composition.
So, in essense, what we have is that, while the resource fetches happen asynchronously, the composition happens serially. This is invaluable, because, since we can guarantee that the composition happens serially, we don’t have to do any special locks or guards for the sum operation. We can safely guarantee that when we are adding the resource size from a given resource fetch, no other operation is happening on the same page, which is a very important consideration when doing computations in multi-threaded programs.
Observations
As we can see here, unlike the Go example , in Java, values are what get composed, and this in turn can lead to a different set of considerations when composing these operations. For example, though everything looks like a CompletableFuture, unless we are careful, we can inadvertently end up blocking threads if we have implicit wait’s in the code.
The other problem we worried about in Go was limiting the number of concurrent connections per host. In the Java code above, the way to address this is to configure the pool properties on AsyncHttpClient to enforce similar concerns.
When composing these operations, the key question will allways be whether to use the method with or without the Async suffix in the name on the CompletableFuture. The Async suffix methods chain the operations on the ForkJoinPool, while the one’s without do it on the completed future’s caller’s thread. So for example, if we have a future that was produced in a ForkJoinPool thread, a chained operation without the Async suffix will run the operation on the same pool thread, while the Async one will shedule a new computation that goes back to the pool.
When working with AsyncHttpClient, in practice, it can be beneficial to chain the first operation using the Async versions so as to free up the I/O thread pool to perform more I/O operations. Otherwise, the rule of thumb would be to consider whether the subsequent operations would be cheap. If it would not be cheap and or need other operations to complete, then it might be preferable to use the Async versions. Otherwise, sync version and help minimize the number of thread context switches within a chain of operations.
Finally, I leave you with this question. How many thread context switches occur in the above code?
The complete code is available on GitHub at https://github.com/satyasm/JavaPageSize if one wants to experiment with it.